Commencer
Table des matières
L'exécutable doxygen est le programme principal qui analyse les sources et génère la documentation. Voir la section Utilisation de Doxygen pour des informations d'utilisation plus détaillées.
En option, l'exécutable doxywizard peut être utilisé, qui est une interface graphique permettant d'éditer le fichier de configuration utilisé par Doxygen et d'exécuter Doxygen dans un environnement graphique. Pour macOS, Doxywizard sera démarré en cliquant sur l'icône de l'application Doxygen.
La figure suivante montre la relation entre les outils et le flux d'informations entre eux (elle semble complexe mais c'est uniquement parce qu'elle essaie d'être complète) :
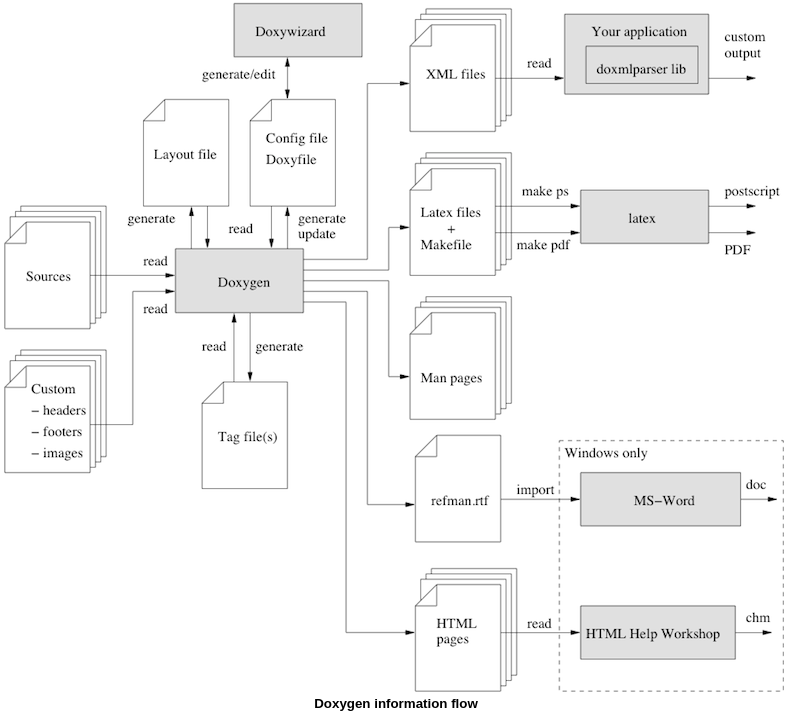
Étape 0 : Vérifiez si Doxygen prend en charge votre langage de programmation/description matérielle
Tout d'abord, assurez-vous que votre langage de programmation/de description matérielle a une chance raisonnable d'être reconnu par Doxygen. Ces langages de programmation sont pris en charge par défaut : C, C++, Lex, C#, Objective-C, IDL, Java, PHP, Python, Fortran et D. Doxygen prend également en charge le langage de description matérielle VHDL par défaut. Il est possible de configurer certaines extensions de type de fichier pour utiliser certains analyseurs : consultez la section Mappages de Configuration/Extension pour plus de détails. De plus, des langages complètement différents peuvent être pris en charge en utilisant des programmes de préprocesseur : consultez les pages d'aides pour plus de détails.
Étape 1 : Création d'un fichier de configuration
Doxygen utilise un fichier de configuration pour déterminer tous ses paramètres. Chaque projet doit avoir son propre fichier de configuration. Un projet peut être constitué d'un seul fichier source, mais peut également être une arborescence source entière qui est analysée de manière récursive.
Pour simplifier la création d'un fichier de configuration, Doxygen peut créer un fichier de configuration modèle pour vous. Pour cela, appelez doxygen depuis la ligne de commande avec l'option -g :
doxygen -g <config-file>
où Doxyfile sera créé. Si un fichier portant le nom stdin), ce qui peut être utile pour les scripts.
Le fichier de configuration a un format similaire à celui d'un Makefile (simple). Il se compose d'un certain nombre d'affectations (balises) de la forme :
TAGNAME = VALUE ou
TAGNAME = VALUE1 VALUE2 ...
Vous pouvez probablement laisser les valeurs de la plupart des balises dans un fichier de configuration de modèle généré à leur valeur par défaut. Voir la section Configuration pour plus de détails sur le fichier de configuration.
Si vous ne souhaitez pas modifier le fichier de configuration avec un éditeur de texte, vous devriez jeter un œil à Doxywizard, qui est une interface graphique qui peut créer, lire et écrire des fichiers de configuration Doxygen, et permet de définir des options de configuration en les saisissant via des boîtes de dialogue.
Pour un petit projet composé de quelques fichiers sources et d'en-têtes C et/ou C++, vous pouvez laisser la balise INPUT vide et Doxygen recherchera les sources dans le répertoire actuel.
Si vous avez un projet plus important composé d'un répertoire ou d'une arborescence source, vous devez affecter le ou les répertoires racine à la balise INPUT et ajouter un ou plusieurs modèles de fichiers à la balise FILE_PATTERNS (par exemple *.cpp *.h). Seuls les fichiers qui correspondent à l'un des modèles seront analysés (si les modèles sont omis, une liste de modèles typiques est utilisée pour les types de fichiers pris en charge par Doxygen). Pour l'analyse récursive d'une arborescence source, vous devez définir la balise RECURSIVE sur YES. Pour affiner davantage la liste des fichiers analysés, les balises EXCLUDE et EXCLUDE_PATTERNS peuvent être utilisées. Pour omettre tous les répertoires de test d'une arborescence source par exemple, on peut utiliser :
EXCLUDE_PATTERNS = */test/*
Doxygen examine l'extension du fichier pour déterminer comment l'analyser, à l'aide du tableau suivant :
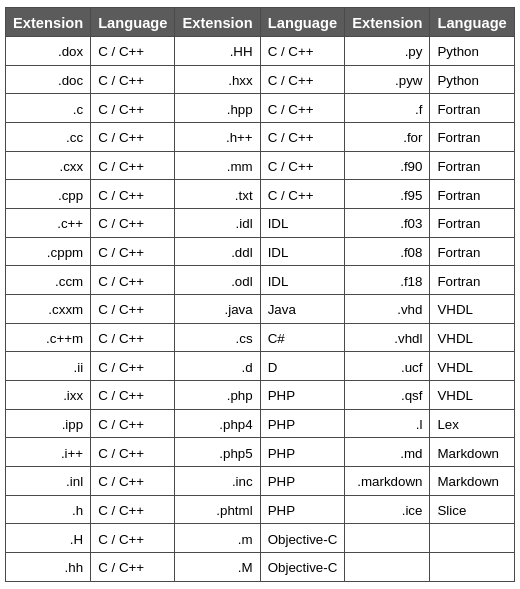
Veuillez noter que la liste ci-dessus peut contenir plus d'éléments que ceux définis par défaut dans FILE_PATTERNS.
Toute extension non analysée peut être définie en l'ajoutant à FILE_PATTERNS et lorsque EXTENSION_MAPPING approprié est défini.
Si vous commencez à utiliser Doxygen pour un projet existant (donc sans aucune documentation dont Doxygen ait connaissance), vous pouvez toujours vous faire une idée de la structure et de l'apparence du résultat documenté. Pour ce faire, vous devez définir la balise EXTRACT_ALL dans le fichier de configuration sur YES. Ensuite, Doxygen fera comme si tout dans vos sources était documenté. Veuillez noter qu'en conséquence, les avertissements concernant les membres non documentés ne seront pas générés tant que EXTRACT_ALL est défini sur YES.
Pour analyser un logiciel existant, il est utile de faire un renvoi entre une entité (documentée) et sa définition dans les fichiers sources. Doxygen générera de telles références croisées si vous définissez la balise SOURCE_BROWSER sur YES. Il est également possible d'inclure les sources directement dans la documentation en définissant INLINE_SOURCES sur YES (cela peut être pratique pour les révisions de code par exemple).
Étape 2 : Exécution de Doxygen
Pour générer la documentation, vous pouvez maintenant saisir :
doxygen <config-file>
En fonction de vos paramètres, Doxygen créera des répertoires html, rtf, latex, xml, man et/ou docbook dans le répertoire de sortie. Comme leur nom l'indique, ces répertoires contiennent la documentation générée au format HTML, RTF, ![]() , XML, Unix-Man page et DocBook.
, XML, Unix-Man page et DocBook.
Le répertoire de sortie par défaut est le répertoire dans lequel doxygen est démarré. Le répertoire racine dans lequel la sortie est écrite peut être modifié à l'aide de OUTPUT_DIRECTORY. Le répertoire spécifique au format dans le répertoire de sortie peut être sélectionné à l'aide des balises HTML_OUTPUT, RTF_OUTPUT, LATEX_OUTPUT, XML_OUTPUT, MAN_OUTPUT et DOCBOOK_OUTPUT du fichier de configuration. Si le répertoire de sortie n'existe pas, doxygen essaiera de le créer pour vous (mais il n'essaiera pas de créer un chemin entier de manière récursive, comme le fait mkdir -p).
Sortie HTML
La documentation HTML générée peut être visualisée en pointant un navigateur HTML vers le fichier index.html dans le répertoire html. Pour obtenir les meilleurs résultats, un navigateur prenant en charge les feuilles de style en cascade (CSS) doit être utilisé (j'utilise Mozilla Firefox, Google Chrome, Safari et parfois IE8, IE9 et Opera pour tester la sortie générée).
Certaines des fonctionnalités de la section HTML (telles que GENERATE_TREEVIEW ou le moteur de recherche) nécessitent un navigateur prenant en charge le HTML dynamique et JavaScript activé.
Sortie LaTeX
La documentation ![]() générée doit d'abord être compilée par un compilateur
générée doit d'abord être compilée par un compilateur ![]() (j'utilise une distribution teTeX récente pour Linux et macOS et MikTex pour Windows). Pour simplifier le processus de compilation de la documentation générée,
(j'utilise une distribution teTeX récente pour Linux et macOS et MikTex pour Windows). Pour simplifier le processus de compilation de la documentation générée, doxygen écrit un Makefile dans le répertoire latex (sur la plate-forme Windows, un fichier batch make.bat est également généré).
Le contenu et les cibles du Makefile dépendent du paramètre USE_PDFLATEX. S'il est désactivé (défini sur NO), en tapant make dans le répertoire latex, un fichier dvi appelé refman.dvi sera généré. Ce fichier peut ensuite être visualisé à l'aide de xdvi ou converti en fichier PostScript refman.ps en tapant make ps (cela nécessite dvips).
Pour mettre 2 pages sur une page physique, utilisez make ps_2on1 à la place. Le fichier PostScript résultant peut être envoyé à une imprimante PostScript. Si vous n'avez pas d'imprimante PostScript, vous pouvez essayer d'utiliser ghostscript pour convertir PostScript en quelque chose que votre imprimante comprend.
La conversion en PDF est également possible si vous avez installé l'interpréteur ghostscript ; tapez simplement make pdf (ou make pdf_2on1).
Pour obtenir les meilleurs résultats pour la sortie PDF, vous devez définir les balises PDF_HYPERLINKS et USE_PDFLATEX sur YES. Dans ce cas, le Makefile ne contiendra qu'une cible pour créer directement refman.pdf.
Sortie RTF
Doxygen combine la sortie RTF en un seul fichier appelé refman.rtf. Ce fichier est optimisé pour l'importation dans Microsoft Word. Certaines informations sont codées à l'aide de ce que l'on appelle des champs. Pour afficher la valeur réelle, vous devez tout sélectionner (Modifier - sélectionner tout), puis basculer entre les champs (clic droit et sélection de l'option dans le menu déroulant).
Sortie XML
La sortie XML consiste en un « dump » structuré des informations collectées par Doxygen. Chaque élément (classe/espace de noms/fichier/...) possède son propre fichier XML et il existe également un fichier d'index appelé index.xml.
Un fichier script XSLT appelé combine.xslt est également généré et peut être utilisé pour combiner tous les fichiers XML en un seul fichier.
Doxygen génère également deux fichiers de schéma XML index.xsd (pour le fichier d'index) et compound.xsd (pour les fichiers composés). Ce fichier de schéma décrit les éléments possibles, leurs attributs et leur structure, c'est-à-dire qu'il décrit la grammaire des fichiers XML et peut être utilisé pour la validation ou pour piloter les scripts XSLT.
Dans le répertoire addon/doxmlparser, vous pouvez trouver une bibliothèque d'analyse pour lire la sortie XML produite par Doxygen de manière incrémentielle (voir addon/doxmlparser/doxmparser/index.py et addon/doxmlparser/doxmlparser/compound.py pour l'interface de la bibliothèque).
Sortie de la page de manuel
Les pages de manuel générées peuvent être visualisées à l'aide du programme man. Vous devez vous assurer que le répertoire man se trouve dans le chemin d'accès man (voir la variable d'environnement MANPATH). Notez qu'il existe certaines limitations aux capacités du format de page de manuel, de sorte que certaines informations (comme les diagrammes de classes, les références croisées et les formules) seront perdues.
Sortie DocBook
Doxygen peut également générer une sortie au format DocBook. Le traitement de la sortie DocBook dépasse le cadre de ce manuel.
Étape 3 : Documenter les sources
Bien que la documentation des sources soit présentée à l'étape 3, dans un nouveau projet, cela devrait bien sûr être l'étape 1. Ici, je suppose que vous possédez déjà du code et que vous voulez que Doxygen génère un joli document décrivant l'API et peut-être les composants internes ainsi que certains documents de conception associés.
Si l'option EXTRACT_ALL est définie sur NO dans le fichier de configuration (par défaut), alors Doxygen ne générera que la documentation pour les entités documentées. Alors, comment les documenter ? Pour les membres, les classes et les espaces de noms, il existe essentiellement deux options :
1 . Placez un bloc de documentation spécial devant la déclaration ou la définition du membre, de la classe ou de l'espace de noms. Pour les membres de fichier, de classe et d'espace de noms, il est également autorisé de placer la documentation directement après le membre.
Voir la section Blocs de commentaires spéciaux pour en savoir plus sur les blocs de documentation spéciaux.
2 . Placez un bloc de documentation spécial ailleurs (un autre fichier ou un autre emplacement) et placez une commande structurelle dans le bloc de documentation. Une commande structurelle lie un bloc de documentation à une certaine entité qui peut être documentée (par exemple un membre, une classe, un espace de noms ou un fichier).
Voir la section Documentation à d'autres endroits pour en savoir plus sur les commandes structurelles.
L'avantage de la première option est que vous n'avez pas à répéter le nom de l'entité.
Les fichiers ne peuvent être documentés qu'à l'aide de la deuxième option, car il n'existe aucun moyen de placer un bloc de documentation avant un fichier. Bien entendu, les membres de fichier (fonctions, variables, typedefs, defines) n'ont pas besoin d'une commande structurelle explicite ; le simple fait de placer un bloc de documentation spécial devant ou derrière eux fonctionnera parfaitement.
Le texte à l'intérieur d'un bloc de documentation spécial est analysé avant d'être écrit dans les fichiers de sortie HTML et/ou ![]() .
.
Lors de l'analyse, les étapes suivantes ont lieu :
- Le formatage Markdown est remplacé par le HTML correspondant ou les commandes spéciales.
- Les commandes spéciales à l'intérieur de la documentation sont exécutées. Voir la section Commandes spéciales pour un aperçu de toutes les commandes.
- Si une ligne commence par un espace suivi d'un ou plusieurs astérisques (*) et éventuellement d'autres espaces, alors tous les espaces et astérisques sont supprimés.
- Toutes les lignes vides résultantes sont traitées comme des séparateurs de paragraphe. Cela vous évite de placer vous-même des commandes de nouveau paragraphe afin de rendre la documentation générée lisible.
- Des liens sont créés pour les mots correspondant aux classes documentées (à moins que le mot ne soit précédé d'un % ; dans ce cas, le mot ne sera pas lié et le signe % sera supprimé).
- Des liens vers les membres sont créés lorsque certains modèles sont trouvés dans le texte. Voir la section Génération automatique de liens pour plus d'informations sur le fonctionnement de la génération automatique de liens.
- Les balises HTML qui se trouvent dans la documentation sont interprétées et converties en équivalents
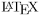 pour la sortie . Voir la section Commandes HTML pour un aperçu de toutes les balises HTML prises en charge.
pour la sortie . Voir la section Commandes HTML pour un aperçu de toutes les balises HTML prises en charge.