Indexation et recherche externes
Table des matières
Introduction
Avec la version 1.8.3, Doxygen offre la possibilité d'effectuer des recherches dans le HTML en utilisant un outil d'indexation et un moteur de recherche externes. Cela présente plusieurs avantages :
- Pour les grands projets, il peut présenter des avantages significatifs en termes de performances par rapport au moteur de recherche intégré de Doxygen, car Doxygen utilise un algorithme d'indexation assez simple.
- Il permet de combiner les données de recherche de plusieurs projets en un seul index, ce qui permet d'effectuer une recherche globale dans plusieurs projets Doxygen.
- Il permet d'ajouter des données supplémentaires à l'index de recherche, c'est-à-dire d'autres pages web non produites par Doxygen.
- Le moteur de recherche doit fonctionner sur un serveur web, mais les clients peuvent toujours parcourir les pages web localement.
Pour éviter que chacun ne doive commencer à écrire son propre indexeur et son propre moteur de recherche, Doxygen fournit un exemple d'outil pour chaque action : doxyindexer pour indexer les données et doxysearch.cgi pour effectuer une recherche dans l'index.
Le flux de données est illustré dans le diagramme suivant :
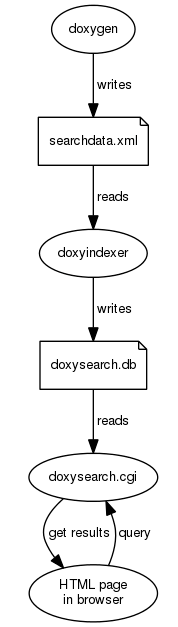
Doxygenproduit les données de recherche brutesDoxyIndexerindexe les données dans une base de données de recherche doxysearch.db- Lorsqu'un utilisateur effectue une recherche à partir d'une page HTML générée par Doxygen, le CGI binaire
doxysearch.cgisera invoqué. - L'outil
doxysearch.cgieffectuera une requête dans la base de données et renverra les résultats. - Le navigateur affichera les résultats de recherche.
Configuration
La première étape consiste à rendre le moteur de recherche disponible via un serveur Web. Si vous utilisez doxysearch.cgi, cela signifie rendre le binaire CGI disponible à partir du serveur Web (c'est-à-dire pouvoir l'exécuter à partir d'un navigateur via une URL commençant par HTTP :)
La configuration d'un serveur web n'entre pas dans le cadre de ce document, mais si, par exemple, Apache est installé, vous pouvez simplement copier le fichier doxysearch.cgi du répertoire binè de Doxygen dans le répertoirecgi-bin` du serveur web Apache. Lisez la documentation d'Apache pour plus de détails.
Pour tester si doxysearch.cgi est accessible, démarrez votre navigateur Web et pointez de l'URL vers le binaire et ajoutez ?test à la fin
http://yoursite.com/path/to/cgi/doxysearch.cgi?test
Vous devriez obtenir le message suivant :
Test failed: cannot find search index doxysearch.db
Si vous utilisez Internet Explorer, vous pouvez être invité à télécharger un fichier, qui contiendra alors ce message.
Puisque nous n'avons pas créé ou installé un doxysearch.db, il est acceptable que le test échoue pour cette raison. Comment corriger ceci est discuté dans la section suivante.
Avant de continuer avec la section suivante, ajoutez l'URL ci-dessus (sans la partie ?test) à la balise SEARCHENGINE_URL dans le fichier de configuration de Doxygen :
SEARCHENGINE_URL = http://yoursite.com/path/to/cgi/doxysearch.cgi
Index de projet unique
Pour utiliser l'option de recherche externe, assurez-vous que les options suivantes sont activées dans le fichier de configuration de Doxygen :
SEARCHENGINE = YES
SERVER_BASED_SEARCH = YES
EXTERNAL_SEARCH = YES
Doxygen génèrera alors un fichier appelé searchdata.xml dans le répertoire de sortie (configuré avec OUTPUT_DIRECTORY).Vous pouvez modifier le nom (et l'emplacement) du fichier avec l'option SEARCHDATA_FILE .
L'étape suivante consiste à mettre les données de recherche brutes dans un index pour une recherche efficace. Vous pouvez utiliser DoxyIndexer pour cela. Exécutez-le simplement à partir de la ligne de commande :
doxyindexer searchdata.xml
Cela créera un répertoire appelé doxysearch.db avec certains fichiers. Par défaut, le répertoire sera créé à l'emplacement à partir du démarrage de DoxyIndexer, mais vous pouvez modifier le répertoire à l'aide de l'option -o.
Copiez le répertoire doxysearch.db dans le même répertoire que l'endroit où se trouve le test doxysearch.cgi et rejouer le test du navigateur en pointant le navigateur vers :
http://yoursite.com/path/to/cgi/doxysearch.cgi?test
Vous devriez maintenant obtenir le message suivant :
Test successful (test réussi)
Maintenant, vous devriez pouvoir rechercher des mots et des symboles à partir de la sortie HTML.
Index multi-projets
Dans le cas où vous avez plus d'un projet Doxygen et que ces projets sont liés, il peut être souhaitable de permettre la recherche de mots dans tous les projets à partir de la documentation de l'un des projets.
Pour ce faire, il suffit de combiner les données de recherche de tous les projets en un seul index, par exemple pour deux projets A et B pour lesquels le fichier searchdata.xml est généré dans les répertoires project_A et project_B exécutez :
doxyindexer project_A/searchdata.xml project_B/searchdata.xml
puis copier le doxysearch.db résultant dans le répertoire où se trouve également doxysearch.cgi.
Le fichier searchdata.xml ne contient pas de chemins ou de liens absolus, alors, comment les résultats de la recherche à partir de plusieurs projets peuvent-ils être liés au bon ensemble de documentation ? C'est là que les options EXTERNAL_SEARCH_ID et EXTRA_SEARCH_MAPPINGS entrent en jeu.
Pour pouvoir identifier les différents projets, il faut définir un ID unique en utilisant EXTERNAL_SEARCH_ID pour chaque projet.
Pour lier les résultats de la recherche au bon projet, vous devez définir un mappage par projet à l'aide de la balise EXTRA_SEARCH_MAPPINGS. Avec cette option pour définir la cartographie des ID d'autres projets à l'emplacement (relatif) de la documentation de ces projets.
Ainsi, pour les projets A et B, la partie pertinente du fichier de configuration pourrait ressembler à la suivante :
project_A/Doxyfile
------------------
EXTERNAL_SEARCH_ID = A
EXTRA_SEARCH_MAPPINGS = B=../../project_B/html
pour le projet A et pour le projet B :
project_B/Doxyfile
------------------
EXTERNAL_SEARCH_ID = B
EXTRA_SEARCH_MAPPINGS = A=../../project_A/html
Avec ces paramètres, les projets A et B peuvent partager la même base de données de recherche, et les résultats de recherche seront liés au bon ensemble de documentation.
Mise à jour index
Lorsque vous modifiez le code source, vous devez réexécuter doxygen pour obtenir à nouveau une documentation à jour. Lorsque vous utilisez la recherche externe, vous devez également mettre à jour l'index de recherche en réexécutant doxyindexer. Vous pouvez regrouper l'appel à doxygen et à doxyindexer dans un script pour faciliter ce processus.
Interface de programmation
Les sections précédentes supposaient que vous utilisiez les outils doxyindexer et doxysearch.cgi pour effectuer l'indexation et la recherche, mais vous pouvez également écrire vos propres outils d'indexation et de recherche si vous le souhaitez.
Pour ces 3 interfaces voici ce qui est important ;
- Le format de l'entrée pour l'outil d'index.
- Le format de l'entrée pour le moteur de recherche.
- Le format de la sortie du moteur de recherche.
Les sous-sections suivantes décrivent plus en détail ces interfaces.
Format d'entrée de l'indexeur
Les données de recherche produites par Doxygen suit le format de message d'index XML SOLR.
L'entrée pour l'indexeur est un fichier XML, qui se compose d'une balise <add> contenant plusieurs balises <doc>, qui à leur tour contiennent plusieurs balises <field>.
Voici un exemple d'un nœud doc, qui contient les données de recherche et les métadonnées pour une méthode :
<add>
...
<doc>
<field name="type">function</field>
<field name="name">QXmlReader::setDTDHandler</field>
<field name="args">(QXmlDTDHandler *handler)=0</field>
<field name="tag">qtools.tag</field>
<field name="url">de/df6/class_q_xml_reader.html#a0b24b1fe26a4c32a8032d68ee14d5dba</field>
<field name="keywords">setDTDHandler QXmlReader::setDTDHandler QXmlReader</field>
<field name="text">Sets the DTD handler to handler DTDHandler()</field>
</doc>
...
</add>
Chaque champ a un nom. Les noms de champ suivants sont pris en charge :
- type: le type de l'entrée de recherche ; peut être l'une d'elles: source, function, slot, signal, variable, typedef, enum, enumvalue, property, event, related, friend, define, file, namespace, concept, group, package, page, dir, module, constants, library, type, union, interface, protocol category, exception, class, struct, service, singleton ;
- name: le nom de l'entrée de recherche; Pour une méthode, il s'agit du nom qualifié de la méthode, pour une classe, c'est le nom de la classe, etc ... ;
- args: la liste des paramètres (en cas de fonctions ou de méthodes) ;
- tag: le nom du fichier de balise utilisé pour ce projet ;
- url: l'URL (relative) à la documentation HTML pour cette entrée ;
- keywords: mots importants qui sont représentatifs pour l'entrée. Lors de la recherche d'un tel mot-clé, cette entrée devrait obtenir un rang plus élevé dans les résultats de recherche ;
- text: la documentation associée à l'élément. Notez que seuls des mots sont présents, pas de balisage.
Note
En raison de la taille potentiellement grande du fichier XML, il est recommandé d'utiliser un analyseur basé SAX pour le traiter.
Format de l'URL de recherche
Lorsque le moteur de recherche est invoqué à partir d'une page HTML générée par le Doxygen, un certain nombre de paramètres sont passés via la chaîne de requête.
Les champs suivants sont passés :
- q: Le texte de la requête tel qu'il est entré par l'utilisateur ;
- n: le nombre de résultats de recherche demandés ;
- p: Le nombre de page de recherche pour retourner les résultats. Chaque page a n valeurs ;
- cb: Le nom de la fonction de rappel, utilisé pour JSON avec le remplissage, voir la section suivante.
À partir de la liste complète des résultats de recherche, la plage [n * p - n * (p + 1) -1] doit être renvoyée.
Voici un exemple de l'apparence d'une requête :
http://yoursite.com/path/to/cgi/doxysearch.cgi?q=list&n=20&p=1&cb=dummy
Il représente une requête pour le mot «liste» (q = list) demandant 20 résultats de recherche (n = 20), en commençant par le numéro de résultat 20 (p = 1) et en utilisant un rappel « fictif » (cb = dummy) :
Note
Les valeurs sont codées par l'URL et doivent donc être décodées avant de pouvoir être utilisées.
Format des résultats de recherche
Lorsque l'on invoque le moteur de recherche comme indiqué dans la sous-section précédente, il doit répondre avec les résultats. Le format de la réponse est JSON avec remplissage, qui est essentiellement une structure JavaScript enveloppée dans un appel de fonction. Le nom de la fonction doit être le nom de la fonction de rappel (tel que transmis avec le champ cb dans la requête).
Avec l'exemple de requête présenté dans la sous-section précédente, la structure principale de la réponse devrait ressembler à ce qui suit :
dummy({
"hits":179,
"first":20,
"count":20,
"page":1,
"pages":9,
"query": "list",
"items":[
...
]})
Les champs ont le sens suivant :
- hits: Le nombre total de résultats de recherche (pourrait être plus que ce qui a été demandé) ;
- first: l'indice du premier résultat renvoyé:
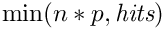 ;
; - count: le nombre réel de résultats renvoyés :
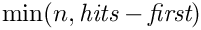 ;
; - page: Le numéro de page du résultat :
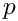 ;
; - pages: le nombre total de pages:
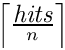 ;
; - item: un tableau contenant les données de recherche par résultat.
Voici un exemple de ce à quoi devrait ressembler un élément du tableau « items » :
{"type": "function",
"name": "QDir::entryInfoList(const QString &nameFilter, int filterSpec=DefaultFilter, int sortSpec=DefaultSort) const",
"tag": "qtools.tag",
"url": "d5/d8d/class_q_dir.html#a9439ea6b331957f38dbad981c4d050ef",
"fragments":[
"Returns a <span class=\"hl\">list</span> of QFileInfo objects for all files and directories...",
"... pointer to a QFileInfoList The <span class=\"hl\">list</span> is owned by the QDir object...",
"... to keep the entries of the <span class=\"hl\">list</span> after a subsequent call to this..."
]
},
Les champs pour un tel élément ont le sens suivant :
- type: Le type de l'élément, comme le montre le champ avec le nom "type" dans les données de recherche brutes ;
- name: le nom de l'élément, y compris la liste des paramètres, comme on le trouve dans les champs avec le nom "name" et "args" dans les données de recherche brutes ;
- tag: le nom du fichier de balise, comme le montre le champ avec le nom "tag" dans les données de recherche brutes ;
- url: le nom de l'URL (relative) à la documentation, comme on le trouve dans le domaine avec le nom "url" dans les données de recherche brutes ;
- "fragments": un tableau avec 0 ou plus de fragments de texte contenant des mots qui ont été recherchés. Ces mots doivent être enveloppés dans les balises
<span class = "hl">et</span>pour les mettre en surbrillance dans la sortie.