Fonctionnalités internes de Doxygen
Fonctionnalités internes de Doxygen
Notez que cette section est toujours en construction !
L'image suivante montre comment les fichiers sources sont traités par Doxygen.
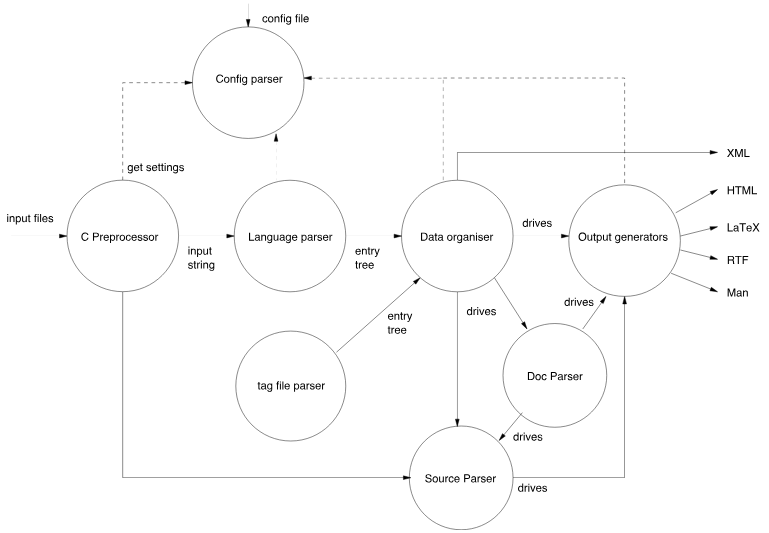
Les sections suivantes expliquent les étapes ci-dessus plus en détail.
Analyseur de configuration
Le fichier de configuration qui contrôle les paramètres d'un projet est analysé et les paramètres sont stockés dans la classe singleton Config dans src/config.h. L'analyseur lui-même est écrit en utilisant flex et peut être trouvé dans src/config.l. Cet analyseur est également utilisé directement par Doxywizard, il est donc placé dans une bibliothèque séparée.
Chaque option de configuration possède l'un des 5 types possibles : String, List, Enum, Int ou Bool. Les valeurs de ces options sont disponibles via les fonctions globales Config_getXXX(), où XXX est le type de l'option. L'argument de ces fonctions est une chaîne nommant l'option telle qu'elle apparaît dans le fichier de configuration. Par exemple : Config_getBool(GENERATE_TESTLIST) renvoie une référence à une valeur booléenne qui est TRUE si la liste de tests a été activée dans le fichier de configuration.
La fonction readConfiguration() dans src/doxygen.cpp lit les options de ligne de commande, puis appelle l'analyseur de configuration.
Préprocesseur C
Les fichiers d'entrée mentionnés dans le fichier de configuration sont (par défaut) transmis au préprocesseur C (après avoir été canalisés via un filtre défini par l'utilisateur, si disponible).
Le fonctionnement du préprocesseur diffère quelque peu d'un préprocesseur C standard. Par défaut, il ne fait pas d'expansion de macro, bien qu'il puisse être configuré pour étendre toutes les macros. L'utilisation typique consiste à étendre uniquement un ensemble de macros spécifié par l'utilisateur. Cela permet par exemple de permettre aux noms de macro d'apparaître dans le type de paramètres de fonction.
Une autre différence est que le préprocesseur analyse, mais n'inclut pas réellement le code lorsqu'il rencontre un #include (à l'exception de #include trouvé à l'intérieur des blocs { ... }). Les raisons derrière cet écart par rapport à la norme sont d'empêcher l'alimentation de plusieurs définitions des mêmes fonctions/classes à l'analyseur de Doxygen. Si tous les fichiers sources incluaient un fichier d'en-tête commun par exemple, les définitions de classe et de type (et leur documentation) seraient présentes dans chaque unité de traduction.
Le préprocesseur est écrit en utilisant flex et peut être trouvé dans src/pre.l. Pour les blocs de conditions (#if), l'évaluation des expressions constantes est nécessaire. Pour cela, un analyseur basé sur yacc est utilisé, qui peut être trouvé dans src/constexp.y et src/constexp.l.
Le préprocesseur est invoqué pour chaque fichier à l'aide de la fonction preprocessFile() déclarée dans src/pre.h, et ajoutera le résultat prétraité à un tampon de caractères. Le format du tampon de caractères est
0x06 nom de fichier 1
0x06 contenu prétraité du fichier 1
...
0x06 nom de fichier n
0x06 contenu prétraité du fichier n
Analyseur de langage
Le tampon d'entrée prétraité est envoyé à l'analyseur de langage, qui est implémenté comme une grande machine à états utilisant flex. Il peut être trouvé dans le fichier src/scanner.l. Il existe un analyseur pour tous les langages (C/C++/Java/IDL). Les variables d'état insideIDL et insideJava sont utilisées à certains endroits pour des choix spécifiques au langage.
La tâche de l'analyseur est de convertir le tampon d'entrée en un arbre d'entrées (essentiellement un arbre de syntaxe abstrait). Une entrée est définie dans src/entry.h et est un blob d'informations vaguement structurées. Le champ le plus important est section qui spécifie le type d'informations contenues dans l'entrée.
Améliorations possibles pour les versions futures :
- Utilisez un scanner/parser par langage au lieu d'un seul gros analyseur.
- Déplacez l'analyse de premier passage des blocs de documentation vers un module séparé.
- Définitions d'analyse (celles-ci sont actuellement collectées par le préprocesseur et ignorées par l'analyseur de langage).
Organisateur de données
Cette étape se compose de plusieurs étapes plus petites, qui construisent des dictionnaires des classes, fichiers, espaces de noms, variables, fonctions, packages, pages et groupes extraits. Outre la construction de dictionnaires, au cours de cette étape, les relations (telles que les relations d'héritage) entre les entités extraites sont calculées.
Chaque étape a une fonction définie dans src/doxygen.cpp, qui opère sur l'arbre d'entrées, construit pendant l'analyse du langage. Consultez la partie « Collecte d'informations » de parseInput() pour plus de détails.
Le résultat de cette étape est un certain nombre de dictionnaires, qui peuvent être trouvés dans l'« espace de noms » Doxygen défini dans src/doxygen.h. La plupart des éléments de ces dictionnaires sont dérivés de la classe Definition ; la classe MemberDef, par exemple, contient toutes les informations pour un membre. Une instance d'une telle classe peut faire partie d'un fichier (classe FileDef), d'une classe (classe ClassDef), d'un espace de noms (classe NamespaceDef), d'un groupe (classe GroupDef) ou d'un package Java (classe PackageDef).
Analyseur de fichiers de balises
Si des fichiers de balises sont spécifiés dans le fichier de configuration, ils sont analysés par un analyseur XML basé sur SAX, qui se trouve dans src/tagreader.cpp. Le résultat de l'analyse d'un fichier de balises est l'insertion d'objets Entry dans l'arborescence des entrées. Le champ Entry::tagInfo est utilisé pour marquer l'entrée comme externe et contient des informations sur le fichier de balises.
Analyseur de documentation
Les blocs de commentaires spéciaux sont stockés sous forme de chaînes dans les entités qu'ils documentent. Il existe une chaîne pour la description brève et une chaîne pour la description détaillée. L'analyseur de documentation lit ces chaînes et exécute les commandes qu'il y trouve (il s'agit de la deuxième étape de l'analyse de la documentation). Il écrit le résultat directement dans les générateurs de sortie.
L'analyseur est écrit en C++ et se trouve dans /docparser.cpp. Les jetons consommés par l'analyseur proviennent de src/doctokenizer.l. Les fragments de code trouvés dans les blocs de commentaires sont transmis à l'analyseur de source.
Le point d'entrée principal de l'analyseur de documentation est validatingParseDoc() déclaré dans src/docparser.h. Pour les textes simples avec des commandes spéciales, validatingParseText() est utilisé.
Analyseur de source
Si la navigation dans la source est activée ou si des fragments de code sont rencontrés dans la documentation, l'analyseur de source est invoqué.
L'analyseur de code essaie de faire des références croisées au code source qu'il analyse avec les entités documentées. Il effectue également la coloration syntaxique des sources. La sortie est directement écrite dans les générateurs de sortie.
Le point d'entrée principal de l'analyseur de code est parseCode() déclaré dans src/code.h.
Générateurs de sortie
Une fois les données collectées et référencées, Doxygen génère une sortie dans différents formats. Pour cela, il utilise les méthodes fournies par la classe abstraite OutputGenerator. Afin de générer une sortie pour plusieurs formats à la fois, les méthodes de OutputList sont appelées à la place. Cette classe maintient une liste de générateurs de sortie concrets, où chaque méthode appelée est déléguée à tous les générateurs de la liste.
Pour permettre de petits écarts dans ce qui est écrit dans la sortie pour chaque générateur de sortie concret, il est possible de désactiver temporairement certains générateurs. La classe OutputList contient diverses méthodes disable() et enable() pour cela. Les méthodes OutputList::pushGeneratorState() et OutputList::popGeneratorState() sont utilisées pour enregistrer temporairement l'ensemble des générateurs de sortie activés/désactivés sur une pile.
Le XML est généré directement à partir des structures de données collectées. À l'avenir, XML sera utilisé comme langage intermédiaire (IL). Les générateurs de sortie utiliseront ensuite cet IL comme point de départ pour générer les formats de sortie spécifiques. L'avantage d'avoir un IL est que divers outils développés indépendamment et écrits dans différents langages pourraient extraire des informations de la sortie XML. Les outils possibles pourraient être :
- un navigateur de sources interactif
- un générateur de diagrammes de classes
- des métriques de code de calcul.
Débogage
Étant donné que Doxygen utilise beaucoup de code flex, il est important de comprendre comment flex fonctionne (pour cela, il faut lire la page de manuel) et de comprendre ce qu'il fait lorsque flex analyse une entrée. Heureusement, lorsque flex est utilisé avec l'option -d, il affiche les règles correspondantes. Cela permet de suivre assez facilement ce qui se passe pour un fragment d'entrée particulier.
Pour faciliter le basculement des informations de débogage pour un fichier flex donné, j'ai écrit le script perl suivant, qui ajoute ou supprime automatiquement -d de la ligne correcte dans le Makefile :
#!/usr/bin/perl
$file = shift @ARGV ;
print "Basculer le mode de débogage pour $file\n" ;
if (!-e "../src/${file}.l")
{
print STDERR "Erreur : le fichier ../src/${file}.l n'existe pas !\n" ;
exit 1 ;
}
system("touch ../src/${file}.l");
unless (rename "src/CMakeFiles/doxymain.dir/build.make","src/CMakeFiles/doxymain.dir/build.make.old") {
print STDERR "Erreur : impossible de renommer src/CMakeFiles/doxymain.dir/build.make !\n";
exit 1 ;
}
if (open(F,"<src/CMakeFiles/doxymain.dir/build.make.old")) {
unless (open(G,">src/CMakeFiles/doxymain.dir/build.make")) {
print STDERR "Erreur : ouverture du fichier build.make pour écriture\n";
exit 1 ;
}
print "Traitement de build.make...\n";
while (<F>) {
if ( s/flex \$\(LEX_FLAGS\) -d(.*) ${file}.l/flex \$(LEX_FLAGS)$1 ${file}.l/ ) {
print "Désactivation des informations de débogage pour $file\n";
}
elsif ( s/flex \$\(LEX_FLAGS\)(.*) ${file}.l$/flex \$(LEX_FLAGS) -d$1 ${file}.l/ ) {
print "Activation des informations de débogage pour $file.l\n";
}
print G "$_";
}
close F;
unlink "src/CMakeFiles/doxymain.dir/build.make.old";
}
else {
print STDERR "Warning file src/CMakeFiles/doxymain.dir/build.make does not exist!\n";
}
# touch the file
$now = time;
utime $now, $now, $file;
Une autre façon d'obtenir des informations de correspondance/débogage des règles à partir du code flex consiste à définir LEX_FLAGS avec make (make LEX_FLAGS=-d).
Par défaut, une version de débogage de Doxygen (c'est-à-dire un exécutable créé avec le paramètre CMake -DCMAKE_BUILD_TYPE=Debug) disposera automatiquement des informations de débogage flex pour tous les fichiers de code flex.
Notez qu'en exécutant Doxygen avec -d lex, vous obtenez des informations sur le fichier de code flex utilisé. Pour voir les informations de l'analyseur flex, qui est compilé avec l'option de débogage flex, vous devez spécifier -d lex:<flex codefile> lors de l'exécution de Doxygen.
Notez que les informations relatives à l'analyse lexicale vont sur stderr et que l'autre sortie de débogage va par défaut sur stdout à moins que l'on utilise -d stderr.
Test
Doxygen dispose d'un petit ensemble de tests disponibles pour tester l'intégrité du code. Les tests peuvent être exécutés au moyen de la commande make tests. Lorsqu'un ou quelques tests seulement sont requis, on peut définir la variable TEST_FLAGS lors de l'exécution du test, par exemple make TEST_FLAGS="--id 5" tests ou pour plusieurs tests make TEST_FLAGS="--id 5 --id 7" tests. Pour un ensemble complet de possibilités, exécutez la commande make TEST_FLAGS="--help" tests. Il est également possible de spécifier TEST_FLAGS comme variable d'environnement (fonctionne également pour les tests via des projets Visual Studio), par exemple setenv TEST_FLAGS "--id 5 --id 7" et make tests.
Différences entre les fichiers Doxyfile
Si l'on doit communiquer via, par exemple, un forum les paramètres de configuration qui sont différents des paramètres du fichier de configuration Doxygen standard, on peut exécuter la commande Doxygen : avec l'option -x et le nom du fichier de configuration (la valeur par défaut est Doxyfile). La sortie sera une liste des paramètres non par défaut (au format Doxyfile). Alternativement, -x_noenv est également possible, ce qui est identique à l'option -x mais sans remplacer les variables d'environnement et les variables de remplacement de type CMake.
Retour à l'index